针对不同问题数据有哪些清洗方式?_变量
数据清洗定义
数据清洗(Data cleaning)– 对数据进行重新审查和校验的过程,目的在于删除重复信息、纠正存在的错误,并提供数据一致性。
数据清洗从名字上也看的出就是把“脏”的“洗掉”,指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。因为数据仓库中的数据是面向某一主题的数据的集合,这些数据从多个业务系统中抽取而来而且包含历史数据,这样就避免不了有的数据是错误数据、有的数据相互之间有冲突,这些错误的或有冲突的数据显然是我们不想要的,称为“脏数据”。我们要按照一定的规则把“脏数据”“洗掉”,这就是数据清洗。而数据清洗的任务是过滤那些不符合要求的数据,将过滤的结果交给业务主管部门,确认是否过滤掉还是由业务单位修正之后再进行抽取。不符合要求的数据主要是有不完整的数据、错误的数据、重复的数据三大类。数据清洗是与问卷审核不同,录入后的数据清理一般是由计算机而不是人工完成。
一致性检查
一致性检查(consistency check)是根据每个变量的合理取值范围和相互关系,检查数据是否合乎要求,发现超出正常范围、逻辑上不合理或者相互矛盾的数据。例如,用1-7级量表测量的变量出现了0值,体重出现了负数,都应视为超出正常值域范围。SPSS、SAS、和Excel等计算机软件都能够根据定义的取值范围,自动识别每个超出范围的变量值。具有逻辑上不一致性的答案可能以多种形式出现:例如,许多调查对象说自己开车上班,又报告没有汽车;或者调查对象报告自己是某品牌的重度购买者和使用者,但同时又在熟悉程度量表上给了很低的分值。发现不一致时,要列出问卷序号、记录序号、变量名称、错误类别等,便于进一步核对和纠正。
无效值和缺失值的处理
由于调查、编码和录入误差,数据中可能存在一些无效值和缺失值,需要给予适当的处理。常用的处理方法有:估算,整例删除,变量删除和成对删除。
估算(estimation)。最简单的办法就是用某个变量的样本均值、中位数或众数代替无效值和缺失值。这种办法简单,但没有充分考虑数据中已有的信息,误差可能较大。另一种办法就是根据调查对象对其他问题的答案,通过变量之间的相关分析或逻辑推论进行估计。例如,某一产品的拥有情况可能与家庭收入有关,可以根据调查对象的家庭收入推算拥有这一产品的可能性。
整例删除(casewise deletion)是剔除含有缺失值的样本。由于很多问卷都可能存在缺失值,这种做法的结果可能导致有效样本量大大减少,无法充分利用已经收集到的数据。因此,只适合关键变量缺失,或者含有无效值或缺失值的样本比重很小的情况。
变量删除(variable deletion)。如果某一变量的无效值和缺失值很多,而且该变量对于所研究的问题不是特别重要,则可以考虑将该变量删除。这种做法减少了供分析用的变量数目,但没有改变样本量。
成对删除(pairwise deletion)是用一个特殊码(通常是9、99、999等)代表无效值和缺失值,同时保留数据集中的全部变量和样本。但是,在具体计算时只采用有完整答案的样本,因而不同的分析因涉及的变量不同,其有效样本量也会有所不同。这是一种保守的处理方法,最大限度地保留了数据集中的可用信息。
采用不同的处理方法可能对分析结果产生影响,尤其是当缺失值的出现并非随机且变量之间明显相关时。因此,在调查中应当尽量避免出现无效值和缺失值,保证数据的完整性。
针对不同问题数据有哪些清洗方式?
1、不完整的数据
不完整的数据是指一条数据中记录某一特征的数据丢失了,比如员工信息表中名叫张三的员工的年龄缺失了。某些数据的缺失值可以从本数据源或其他数据源推导出来,像上例中的员工年龄就可以根据身份证号计算出来。除了这种特殊关系的数据缺失外,其他数据的缺失常用的清洗方法还有取平均值、最大值、最小值、计算结果值,或者取其他字段的值等等。
2、重复的数据
重复的数据就是相同的一条数据出现了两次或以上,对于重复的数据清洗起来比较简单,只需要根据主键或者其他规则删除多余的数据即可。
3、错误的数据
错误的数据又可以分成格式错误和内容错误两种。格式错误是指我们收集到的数据的格式跟我们期望的数据格式不一致,比如设计的库表字段为8位的日期“20200604”格式,但我们获取到的数据为“2020-06-04”,这种数据肯定是存不进数据库的,需要将其清洗成8位的日期字符串,我们可以先将“2020-06-04”转换为日期型的数据,然后再将日期转换为“YYYYMMDD”格式的字符串,也可以采用字符串分割在拼接的方法,依次取“2020-06-04”的1-4、6-7、9-10位拼接成一个新的字符串。
内容错误的数据检测处理则稍麻烦些,需要数据处理人员通过分析来找出脏数据。我们可以通过简单的黑名单或白名单来找出脏数据,只要一列数据中出现了黑名单上的值,就认为该数据是脏数据,并将其替换为我们预先准备好的指定值。
今天给大家推荐的是亿信华辰旗下的数据工厂软件(EsDataFactory)。数据工厂是亿信华辰经过十多年的数据仓库和商业智能项目管理以及实施经验总结、知识沉淀,全力打造的一款同时满足大中小型数据集成和数据管控的实施利器,很大程度上能降低数据集成实施技术门槛,使复杂、重复性的工作简单及智能化。
下面,我们就来看一下数据工厂的厉害之处吧。
数据工厂登录界面
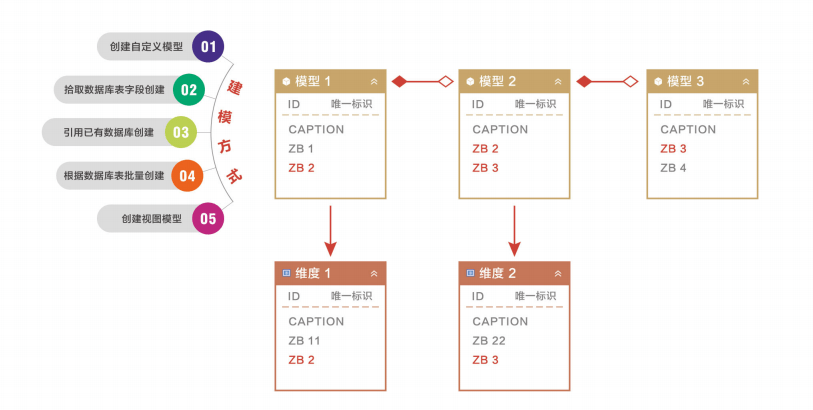
多视角多方式可视化建模
数据工厂提供了可视化定义的方式来完成数据模型的创建,支持自定义创建,同时也可从现有的数据结构(数据库表、视图、文件等)中挑选字段进行创建,提供全局视图用于呈现模型以及模型与维度之间的关联关系,支持范式模型、星型模型和雪花模型的定义。
增量捕获和数据装载
数据工厂提供了基于时间戳、MD5、触发器、全表比较等多种方式变化数据捕获机制,对用户透明,只需要简单设置即可完成增量数据获取,提供数据覆盖、数据追加、数据更新和更新插入等多种数据的落地装载策略,全面覆盖数据落地场景。

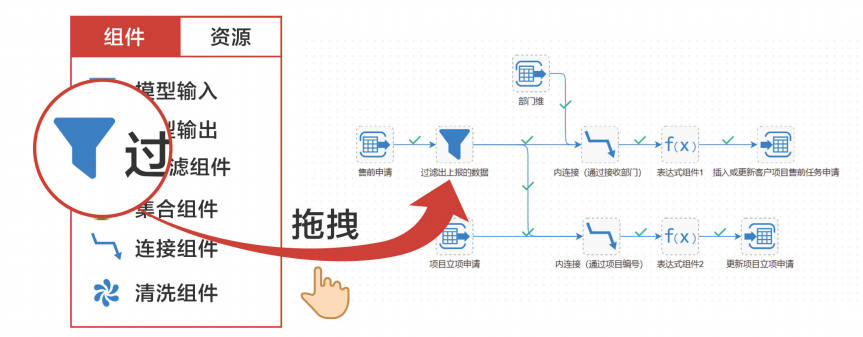
拖拽式流程设计器
数据工厂采用全拖拽式流程设计器,用户只需要在简单拖拽数据资源和加工组件就可完成复杂的ETL作业和作业流程的定义,“零”编码,易操作、易阅读、易维护。另外,支持完整图形编辑功能,如复制、粘贴、撤销、重做、自动对齐等。
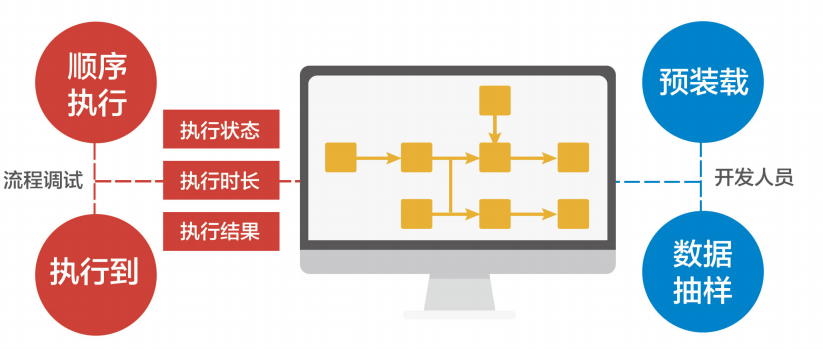
可视化调试和预装载
支持流程调试,如顺序执行、执行到功能,可以查看每步的执行状态、执行时长和执行结果集,同时面向开发人员设置了预装载机制和数据抽样加载,方便开发人员快速验证流程和调试脚本。
丰富的数据处理组件
数据工厂提供了50余种数据处理组件,用于完成数据的传输、清洗转换、装载落地。扁平化图标设计,详细的在线帮助手册和案例库,让用户很轻易就能上手使用。
多重登录认证
提供Ukey签名及用户角色权限双重认证机制,从访问资源控制系统受控访问,杜绝非法访问,降低事件风险发生率。
