Python数据挖掘教与学(教学大纲+教案+视频,魏伟一)_学时_要求_处理
 Python数据挖掘教与学(教学大纲+教案+视频,魏伟一) 12:47 广告 广告 广告
秒后跳过广告
Python数据挖掘教与学(教学大纲+教案+视频,魏伟一) 12:47 广告 广告 广告
秒后跳过广告 开通搜狐视频黄金会员,尊享更高品质体验!
1080P及以上画质仅为
抱歉,您观看的视频加载失败 请检查网络连接后重试,有话要说?请点击 正在切换清晰度... 播放 按esc可退出全屏模式 00:00 00:00 07:05 广告 只看TA 高清 倍速 剧集 字幕 字幕 下拉浏览更多 5X进行中 炫彩HDRVIP尊享HDR视觉盛宴 超清 720P 高清 540P 2.0x 1.5x 1.25x 1.0x 0.8x 50 哎呀,什么都没识别到 反馈 循环播放 跳过片头片尾 画面色彩调整 AI明星识别 视频截取 跳过片头片尾 | 色彩调整 亮度 标准 饱和度 100 对比度 100 恢复默认设置 关闭 单语言 双语言 选择显示语言 中文 English 主字幕(上方) 中文 English 副字幕(下方) 中文 English 关闭 复制全部log 关闭 视频编码: avc1.4d401f(Main @L3.1) 音频编码: mp4a.40.5(MP4 AAC 44.1khz) 网络类型: p2p 视频格式: mp4 视频协议: https 音量: 50% 分辨率: 2048x1152 视频高宽: 1366x768 缓冲数据: 0.000 KB/s 下载速度: 0.574 MB/s 帧数: 10625(0/10625) f DRM类型: false
数据挖掘与机器学习教学大纲
01
课程简介
数据挖掘与机器学习是数据科学与大数据技术专业的一门核心基础课,也是进行数据分析和处理必不可少的基础。通过本课程的学习,使学生掌握数据预处理技术(包括数据度量、数据清理、数据集成和转换等方法)和数据挖掘与机器学习技术(包括分类、预测、关联和聚类的概念与技术),并且熟悉数据挖掘与机器学习基本原理和发展方向,提升解决复杂数据工程问题能力,激发学生科技报国的家国情怀和使命担当,锻炼创造性思维和创新性实践能力,具备初步的科研能力和创造能力。
数据挖掘与机器学习作为理论和实践结合的课程,其先修课是概率论与数理统计、Python数据分析与可视化、优化理论与应用,这三门课程为本课程提供理论基础与实践工具。本课程也是行业大数据分析、大数据处理综合实践、数据挖掘课程设计等专业课的重要基础。
02
课程内容及要求
(一)引言(2学时)
1. 教学内容
理论教学(2学时):
(1)掌握数据挖掘与机器学习的概念、内容。
(2)数据挖掘的任务、数据源、存在的问题与常用工具。
(3)数据挖掘与机器学习课程的核心地位和学习目标(思政教育内容:我国大数据政务平台、大数据医疗平台等优秀的公司案例,展示中国目前蓬勃开展的数据挖掘技术,培养学生的爱国情怀,同时帮助学生树立专业自信心)。
2. 基本要求
(1)数据分析与数据挖掘的基本内容及其联系和区别,数据挖掘与机器学习的基本内容及其联系和区别。
(2)要求学生掌握数据挖掘和机器学习中存在的主要问题,数据建模的常用工具以及Python数据挖掘与机器学习的常用库。
3. 重点及难点
重点:数据挖掘与机器学习的基本流程。
难点:数据挖掘与机器学习的主要问题。
4. 教学模式:课堂讲述与讨论
5. 作业及课外学习要求
(1)要求学生完成数据挖掘与机器学习基本概念的知识性作业;
(2)要求学生阅读文献或查阅资料,完成数据挖掘与机器学习发展的综述性书面作业;
(二)认识数据(4学时)
1. 教学内容:
理论教学(2学时)
(1)数据对象的属性及其类型。
(2)数据的基本统计描述。
(3)数据可视化。
(4)数据对象的相似性度量。(思政融入点:特征选择时,通过算法选择出对识别有重大贡献的特征,坚决淘汰不良文化(贡献小)的影响。)
实验教学(2学时)
(1)数据对象及其相似性度量的Python实现。
(2)数据对象的统计描述及Python和Scipy实现。
2. 基本要求:
(1)掌握数据对象及其属性和类型;
(2)掌握数据对象的相似性度量;
(3)掌握并能实验数据中心趋势和散度的度量方法,数据直方图、散点图等数据可视化方法,数据相似性和相异性的度量方法。
3. 重点及难点:
重点:数据对象的属性类型、相似性度量。
难点:具有混合数据类型属性的数据对象相似性度量。
4. 教学模式:课堂讲述与讨论,上机实验
5. 作业及课外学习要求
(1)要求学生完成数据对象相关基本概念的知识性作业;
(2)要求学生完成数据对象相似性度量的习题;
(3)要求学生编程环境中完成数据对象的相似性度量和数据的统计描述;
(三)数据预处理(6学时)
1. 教学内容:
理论教学(4学时)
(1)数据预处理的必要性。
(2)数据清洗。
(3)数据异常值检测。
(4)数据集成。
(5)数据标准化。
(6)数据规约(思政融入点:“横看成岭侧成峰,远近高低各不同”,从不同维度探索高维数据,看清事物全貌。)。
实验教学(2学时)
(1)利用Pandas进行数据清洗。
(2)利用sklearn进行数据预处理。
2. 基本要求:
(1)掌握数据预处理的基本过程;
(2)掌握数据预处理的算法和方法;
(3)掌握并能实验处理数据相关性的方法、数据规范化方法以及主成分分析方法。
3. 重点及难点:
重点:数据预处理的内容及其典型算法和方法。
难点:数据规约中的属性选择、维度规约、数据压缩以及傅里叶变换、小波变换和PCA主成分分析。
4. 教学模式:课堂讲述与讨论,上机实验
5. 作业及课外学习要求
(1)要求学生完成数据预处理相关基本概念的知识性作业;
(2)要求学生完成数据异常值检测编程实现;
(3)要求学生编程实现PCA数据属性约减;
(4)要求学生查阅资料,完成数据预处理综述的书面作业。
(四)数据仓库与联机分析处理(6学时)
1. 教学内容:
理论教学(4学时)
(1)数据仓库体系结构。
(2)数据ETL。
(3)数据集市。
(4)元数据库。
(5)多维数据模型。
(6)OLAP基本分析操作。
(7)数据仓库维度建模。
实验教学(2学时)
(1)数据仓库的设计。
(2)利用hive进行数据仓库操作。
2. 基本要求:
(1)掌握数据仓库的基本概念;
(2)OLTP与OLAP的区别;
(3)数据仓库的设计与使用;
3. 重点及难点:
重点:数据仓库及其OLAP分析。
难点:数据仓库的维度建模。
4. 教学模式:课堂讲述与讨论,上机实验
5. 作业及课外学习要求
(1)要求学生完成数据仓库相关基本概念的知识性作业;
(2)要求学生查阅资料,完成数据仓库发展综述的书面作业。
(五)回归分析(6学时)
1. 教学内容:
理论教学(4学时)
(1)回归分析概述。
(2)一元线性回归分析。
(3)多元线性回归。
(4)逻辑回归。
(5)多项式回归。
(6)其他回归分析方法。
实验教学(2学时)
(1)回归分析的一般过程。
(2)回归分析的Python实现。
2. 基本要求:
(1)掌握数据分析回归分析的过程;
(2)掌握一元线性回归模型的参数估计;
(3)理解多元线性回归模型;
(4)了解多元线性回归的假设检验及其评价;
(5)掌握逻辑回归;
(6)掌握岭回归、lasso回归及弹性回归和逐步回归;
(7)掌握利用Python进行数据的回归分析;
3. 重点及难点:
重点:线性回归、多项式回归。
难点:回归分析中的过拟合及正则化处理。
4. 教学模式:课堂讲述与讨论,上机实验
5. 作业及课外学习要求
(1)要求学生完成回归分析相关基本概念的知识性作业;
(2)要求学生完成数据回归分析实验。
(六)关联分析分析(6学时)
1. 教学内容:
理论教学(4学时)
(1)关联规则分析概述
(2)频繁项集挖掘方法(融入点:在Apriori算法中,计算频繁项集需要屡次重复扫描数据库,引导学生“成功不是一蹴而就的,需多维度培养和做炼自己的耐心”,强调工匠精神的重要性。)
(3)关联规则评估方法
实验教学(2学时)
(1)Apriori算法及其应用。
(2)FP-growth算法及其应用。
2. 基本要求:
(1)理解了解关联规则的基本思想、概念和意义;
(2)熟练掌握频繁项集、闭项集和关联规则的概念;
(3)理解频繁模式挖掘的路线图;
(4)掌握Apriori 算法:使用候选项集找频繁项集;
(5)掌握由频繁项集产生关联规则的方法;
(6)理解提高Apriori 算法有效性的方法;
(7)掌握挖掘频繁项集的模式增长方法;
(8)理解解强关联规则不一定是有趣的;
(9)使用提升度进行相关分析;
3. 重点及难点:
重点:Apriori算法及其应用。
难点:FP-growth算法。
4. 教学模式:课堂讲述与讨论,上机实验
5. 作业及课外学习要求
(1)要求学生完成回归分析相关基本概念的知识性作业;
(2)Apriori算法解决频繁项挖掘;
(2)要求学生完成数据关联分析实验;
(七)分类(有监督学习)(14学时)
1. 教学内容:
理论教学(8学时)
(1)分类的基本思想;
(2)典型的分类算法:决策树规约、KNN、SVM、朴素贝叶斯;
(3)模型评估与选择;(思政融入点:将分类中常见的过度拟合现象,引入结合孔子在《论语先进》中“过犹不及”的案例进行阐述分析,任何事都要有限度,适可而止,潜移默化生活处世哲学“物极必反,盛极而衰”的道理。)
(4)组合学习;
(5)利用Python实现模型的评估与选择;
实验教学(6学时)
(1)典型分类算法及其应用。
(2)模型评估与选择。
2. 基本要求:
(1)理解分类及预测的基本思想、概念和意义;
(2)掌握常用的分类及预测算法(或模型);
(3)掌握利用Python实现各种分类算法的方法;
(4)掌握分类算法的评估与模型选择方法;
(5)掌握集成学习的思想,随机森林实现;
3. 重点及难点:
重点:分类算法(决策树、SVM、朴素贝叶斯、KNN)及其应用。
难点:模型评估与选择。
4. 教学模式:课堂讲述与讨论,上机实验
5. 作业及课外学习要求
(1)要求学生完成数据分类相关基本概念的知识性作业;
(2)典型分类算法实现;
(八)聚类(无监督学习)(12学时)
1. 教学内容:
理论教学(8学时)
(1)聚类分析的概念;
(2)K-Means聚类;
(3)层次聚类方法;
(4)基于密度的方法;
(5)其他聚类算法(FCM聚类,EM聚类);
(6)聚类评估;(思政融入点:1.“物以类聚、人以群分”,生活中很多事物因某些内在特征呈现出自动聚集特征,引入聚类分析的算法思想;2.飞行数据聚类分析,分析飞行数据之间关联和飞行行为效能评估,树立利用科技解决实际问题的意识。)
(7)利用Python实现聚类算法;
实验教学(4学时)
(1)典型聚类算法及其应用。
(2)聚类模型的评估。
2. 基本要求:
(1)掌握K-Means聚类、层次聚类、基于密度的聚类和其他常用方法;
(2)掌握聚类模型的评估方法;
(3)掌握利用sklearn实现聚类的方法;
3. 重点及难点:
重点:典型聚类算法及其性能评估。
难点:EM算法。
4. 教学模式:课堂讲述与讨论,上机实验
5. 作业及课外学习要求
(1)要求学生完成数据聚类相关基本概念的知识性作业;
(2)典型聚类算法实现;
(3)查阅资料或阅读文献,完成聚类分析发展的综述性书面作业;
(九)神经网络(4学时)
1. 教学内容:
理论教学(2学时)
(1)神经网络基础;
(2)BP神经网络;
(3)深度学习及CNN介绍;
实验教学(2学时)
(1)BP算法实现。
(2)BP算法应用及Sklearn实现。
2. 基本要求:
(1)掌握感知机与BP神经网络的原理;
(2)了解深度学习基础;
(4)掌握利用Python实现BP网络;
3. 重点及难点:
重点:BP神经网络。
难点:BP算法实现。
4. 教学模式:课堂讲述与讨论,上机实验
5. 作业及课外学习要求
(1)要求学生完成神经网络相关基本概念的知识性作业;
(2)BP算法实现;
(十)离群点检测(4学时)
1. 教学内容:
理论教学(2学时)
(1)离群点概述;
(2)离群点分类;
(3)离群点检测常用方法;(思政融入点融入点:1.使用离群点检验可以检测出保险欺诈、电信诈骗、信用卡盗刷、电子商务欺诈等小概率事件,引入知名影星偷税漏税的案例,教育学生要具备正确的三观,不违法乱纪、不存片幸心理,脚踏实地做人做事;2.离群点通常会被当作噪声而忽略,这就需要学生在数据挖掘过程中学会辩证看待问题,具体情况具体分析。)
(4)sklearn中的异常值检测方法;
实验教学(2学时)
(1)典型聚类算法及其应用。
(2)聚类模型的评估。
2. 基本要求:
(1)理解离群点的概念和类型;
(2)理解离群点检测的挑战;
(3)理解基于统计学的离群点检测方法;
(4)理解基于临近性的离群点检测方法;
(5)理解基于聚类的离群点检测方法;
(6)掌握利用Python进行异常值检测的方法。
3. 重点及难点:
重点:典型离群点检测算法及其应用。
难点:离群点的预测。
4. 教学模式:课堂讲述与讨论,上机实验
5. 作业及课外学习要求
(1)要求学生完成数据离群点检测相关基本概念的知识性作业;
(2)典型离群点检测算法实现;
(3)查阅资料或阅读文献,完成离群点检测的综述性书面作业;
(十一)时序数据与文本数据挖掘(8学时)
1. 教学内容:
理论教学(4学时)
(1)文本数据挖掘方法;
(2)时序数据挖掘方法;
实验教学(4学时)
(1)时序数据分析应用。
(2)文本数据分析应用。
2. 基本要求:
(1)掌握文本数据挖掘内容与时序数据挖掘方法;
(2)掌握利用Python进行综合数据分析;
3. 重点及难点:
重点:文本数据与时序数据分析挖掘。
难点:时序数据挖掘。
4. 教学模式:课堂讲述与讨论,上机实验
5. 作业及课外学习要求
(1)时序数据与文本数据挖掘应用;
(3)查阅资料或阅读文献,完成文本数据挖掘技术发展的综述性书面作业;
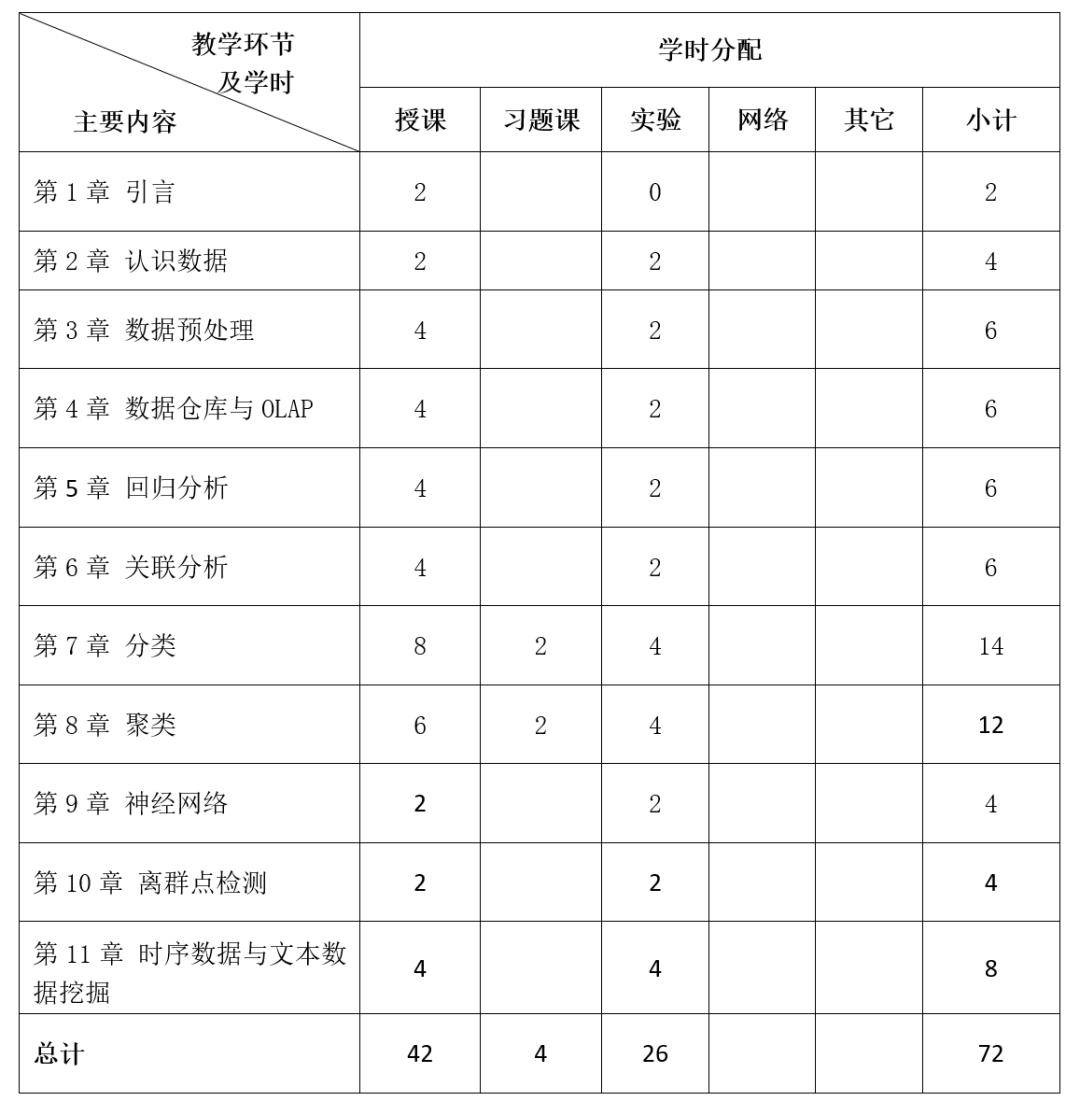
03
教学安排及学时分配
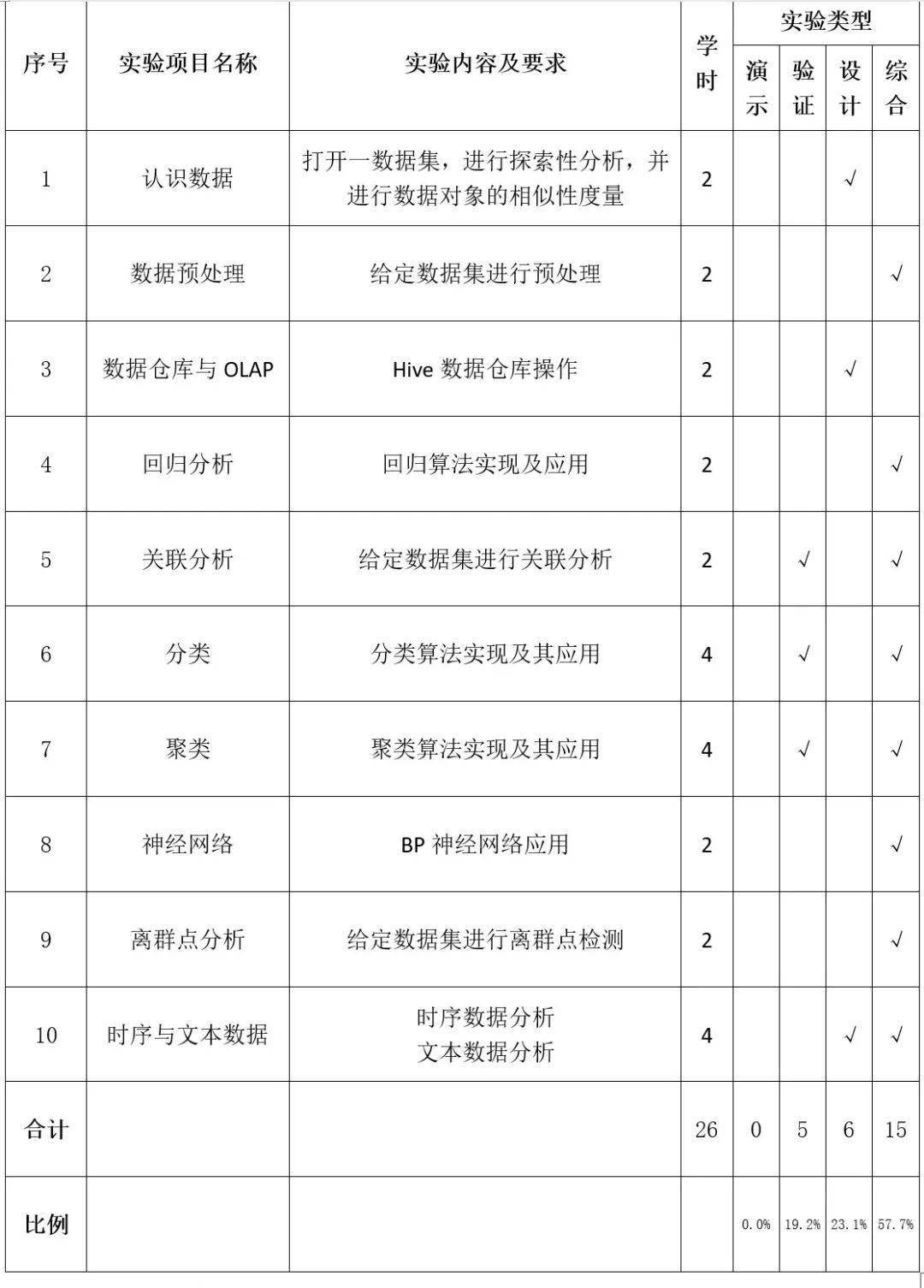
04
实验部分教学内容和要求
05
课程考核与评价
课程考核总评成绩(满分100)=平时成绩(满分100,占比10%)+课内实验成绩(满分100,占比20%)+期中考试(满分100分,占20%)+期末考试成绩(满分100分,占比50%)
1. 平时考核:主要考核各单元知识点的复习、理解和掌握程度,每次课堂讨论、课堂测验、平时作业和网络学习的完成情况。
2. 实验考核:主要考查学生实践动手能力和开发工具的掌握情况及每次实验的完成情况。
3. 期中考试:主要考核对课程的前6章掌握情况,并起到查漏补缺和督促的作用。
4. 期末考试:主要考核对课程的知识点掌握程度以及运用理论知识解决实际问题的能力。
06
选用教材

扫码,限量优惠购书
10
内容简介
本书主要介绍数据挖掘与机器学习的基本概念和方法,包括绪论、Python数据分析与挖掘基础、认识数据、数据预处理、回归分析、关联规则挖掘、分类、聚类、神经网络与深度学习、离群点检测、文本和时序数据挖掘、数据挖掘案例等内容。
各章力求原理叙述清晰,易于理解,突出理论联系实际,辅以Python代码实践与指导,引领读者更好地理解与应用算法,快速迈进数据挖掘领域,掌握机器学习算法的理论和应用。
本书可作为高等学校计算机科学与技术、数据科学与大数据技术等相关专业的教材,也可作为科研人员、工程师和大数据爱好者的参考书。
11
目录
上下滚动查看 ↓
目录
扫一扫
源码下载
第1章绪论
1.1数据挖掘简介
1.2数据分析与数据挖掘
1.3数据挖掘的主要任务
1.3.1关联分析
1.3.2数据建模预测
1.3.3聚类分析
1.3.4离群点检测
1.4数据挖掘的数据源
1.4.1数据库数据
1.4.2数据仓库
1.4.3事务数据库
1.4.4其他类型数据
1.5数据挖掘使用的技术
1.5.1统计学
1.5.2机器学习
1.5.3数据库管理系统与数据仓库
1.6数据挖掘存在的主要问题
1.7数据挖掘建模的常用工具
1.7.1商用工具
1.7.2开源工具
1.8为何选用Python进行数据挖掘
1.9Python数据挖掘常用库
1.10Jupyter Notebook的使用
1.11小结
习题1
第2章Python数据分析与挖掘基础
2.1Python程序概述
2.1.1基础数据类型
2.1.2变量和赋值
2.1.3运算符和表达式
2.1.4字符串
2.1.5流程控制
2.1.6函数
2.2内建数据结构
2.2.1列表
2.2.2元组
2.2.3字典
2.2.4集合
2.3NumPy数值运算基础
2.3.1创建数组对象
2.3.2ndarray对象属性和数据转换
2.3.3生成随机数
2.3.4数组变换
2.3.5数组的索引和切片
2.3.6数组的运算
2.3.7NumPy中的数据统计与分析
2.4Pandas统计分析基础
2.4.1Pandas中的数据结构
2.4.2索引对象
2.4.3查看DataFrame的常用属性
2.4.4DataFrame的数据查询与编辑
2.4.5Pandas数据运算
2.4.6函数应用与映射
2.4.7排序
2.4.8汇总与统计
2.4.9数据分组与聚合
2.4.10Pandas数据读取与存储
2.5Matplotlib图表绘制基础
2.5.1Matplotlib简介
2.5.2Matplotlib绘图基础
2.5.3设置pyplot的动态rc参数
2.5.4文本注解
2.5.5pyplot中的常用绘图
2.6scikitlearn
2.6.1scikitlearn简介
2.6.2scikitlearn中的数据集
2.6.3scikitlearn的主要功能
2.7小结
习题2
本章实训: 体检数据分析与可视化
第3章认识数据
3.1属性及其类型
3.1.1属性
3.1.2属性类型
3.2数据的基本统计描述
3.2.1中心趋势度量
3.2.2数据散布度量
3.3数据可视化
3.3.1基于像素的可视化技术
3.3.2几何投影可视化技术
3.3.3基于图符的可视化技术
3.3.4层次可视化技术
3.3.5可视化复杂对象和关系
3.3.6高维数据可视化
3.3.7Python可视化
3.4数据对象的相似性度量
3.4.1数据矩阵和相异性矩阵
3.4.2标称属性的相似性度量
3.4.3二元属性的相似性度量
3.4.4数值属性的相似性度量
3.4.5序数属性的相似性度量
3.4.6混合类型属性的相似性
3.4.7余弦相似性
3.4.8距离度量Python实现
3.5小结
习题3
本章实训: 数据探索性分析
第4章数据预处理
4.1数据预处理的必要性
4.1.1原始数据中存在的问题
4.1.2数据质量要求
4.2数据清洗
4.2.1数据清洗方法
4.2.2利用Pandas进行数据清洗
4.3数据集成
4.3.1数据集成过程中的关键问题
4.3.2利用Pandas合并数据
4.4数据标准化
4.4.1离差标准化数据
4.4.2标准差标准化数据
4.5数据归约
4.5.1维归约
4.5.2数量归约
4.5.3数据压缩
4.6数据变换与数据离散化
4.6.1数据变换的策略
4.6.2Python数据变换与离散化
4.7利用scikitlearn进行数据预处理
4.8小结
习题4
本章实训: 用电量数据预处理
第5章回归分析
5.1回归分析概述
5.1.1回归分析的定义与分类
5.1.2回归分析的过程
5.1.3回归算法的评价
5.2一元线性回归分析
5.2.1一元线性回归方法
5.2.2一元线性回归模型的参数估计
5.2.3一元线性回归模型的误差方差估计
5.2.4一元回归模型的主要统计检验
5.2.5一元线性回归的Python实现
5.3多元线性回归
5.3.1多元线性回归模型
5.3.2多元线性回归模型的参数估计
5.3.3多元线性回归的假设检验及其评价
5.3.4多元线性回归的Python实现
5.4逻辑回归
5.4.1逻辑回归模型
5.4.2逻辑回归的Python实现
5.5其他回归分析
5.5.1多项式回归
5.5.2岭回归
5.5.3Lasso回归
5.5.4弹性网络回归
5.5.5逐步回归
5.6小结
习题5
本章实训: 糖尿病数据的回归分析
第6章关联规则挖掘
6.1关联规则分析概述
6.2频繁项集、闭项集和关联规则
6.3频繁项集挖掘方法
6.3.1Apriori算法
6.3.2由频繁项集产生关联规则
6.3.3提高Apriori算法的效率
6.3.4频繁模式增长算法
6.3.5使用垂直数据格式挖掘频繁项集
6.4关联模式评估方法
6.4.1强关联规则不一定是有趣的
6.4.2从关联分析到相关分析
6.5Apriori算法应用
6.6小结
习题6
本章实训: 毒蘑菇特征分析
第7章分类
7.1分类概述
7.2决策树归纳
7.2.1决策树原理
7.2.2ID3算法
7.2.3C4.5算法
7.2.4CART算法
7.2.5树剪枝
7.2.6决策树应用
7.3K近邻算法
7.3.1算法原理
7.3.2Python算法实现
7.4支持向量机
7.4.1算法原理
7.4.2Python算法实现
7.5贝叶斯分类方法
7.5.1算法原理
7.5.2朴素贝叶斯分类
7.5.3高斯朴素贝叶斯分类
7.5.4多项式朴素贝叶斯分类
7.5.5朴素贝叶斯分类应用
7.6模型评估与选择
7.6.1分类器性能的度量
7.6.2模型选择
7.7组合分类
7.7.1组合分类方法简介
7.7.2袋装
7.7.3提升和AdaBoost
7.7.4随机森林
7.8小结
习题7
本章实训: 乳腺癌预测
第8章聚类
8.1聚类分析概述
8.1.1聚类分析的概念
8.1.2聚类算法分类
8.2KMeans聚类
8.2.1算法原理
8.2.2算法改进
8.2.3KMeans算法实现
8.3层次聚类
8.3.1算法原理
8.3.2簇间的距离度量
8.3.3凝聚层次聚类
8.3.4分裂层次聚类
8.3.5层次聚类应用
8.4基于密度的聚类
8.4.1算法原理
8.4.2算法改进
8.4.3DBSCAN算法实现
8.5其他聚类方法
8.5.1STING聚类
8.5.2概念聚类
8.5.3模糊聚类
8.5.4高斯混合模型聚类
8.5.5近邻传播聚类
8.6聚类评估
8.6.1聚类趋势的估计
8.6.2聚类簇数的确定
8.6.3聚类质量的测定
8.7小结
习题8
本章实训: 鸢尾花数据聚类分析
第9章神经网络与深度学习
9.1神经网络基础
9.1.1神经元模型
9.1.2感知机与多层网络
9.2BP神经网络
9.2.1多层前馈神经网络
9.2.2后向传播算法
9.2.3BP神经网络应用
9.3深度学习
9.3.1深度学习概述
9.3.2常用的深度学习算法
9.4小结
习题9
本章实训: 应用BP神经网络实现鸢尾花分类
第10章离群点检测
10.1离群点概述
10.1.1离群点的概念
10.1.2离群点的类型
10.1.3离群点检测的挑战
10.2离群点的检测
10.2.1基于统计学的离群点检测
10.2.2基于邻近性的离群点检测
10.2.3基于聚类的离群点检测
10.2.4基于分类的离群点检测
10.3scikitlearn中的异常检测方法
10.4小结
习题10
本章实训: 离群点检测
第11章文本和时序数据挖掘
11.1文本数据挖掘
11.1.1文本挖掘概述
11.1.2文本挖掘的过程与任务
11.1.3文本分析与挖掘的主要方法
11.2时序数据挖掘
11.2.1时间序列和时间序列数据分析
11.2.2时间序列平稳性和随机性判定
11.2.3自回归滑动平均模型(ARMA)
11.2.4差分整合移动平均自回归模型(ARIMA)
11.2.5季节性差分自回归移动平均模型(SARIMA)
11.3小结
习题11
第12章数据挖掘案例
12.1泰坦尼克号乘客生还预测
12.2使用逻辑回归、SVM和BP神经网络进行手写体数字识别
12.3客户数据聚类分析
12.4图像的聚类分割
12.5小结
参考文献
12
配套视频演示
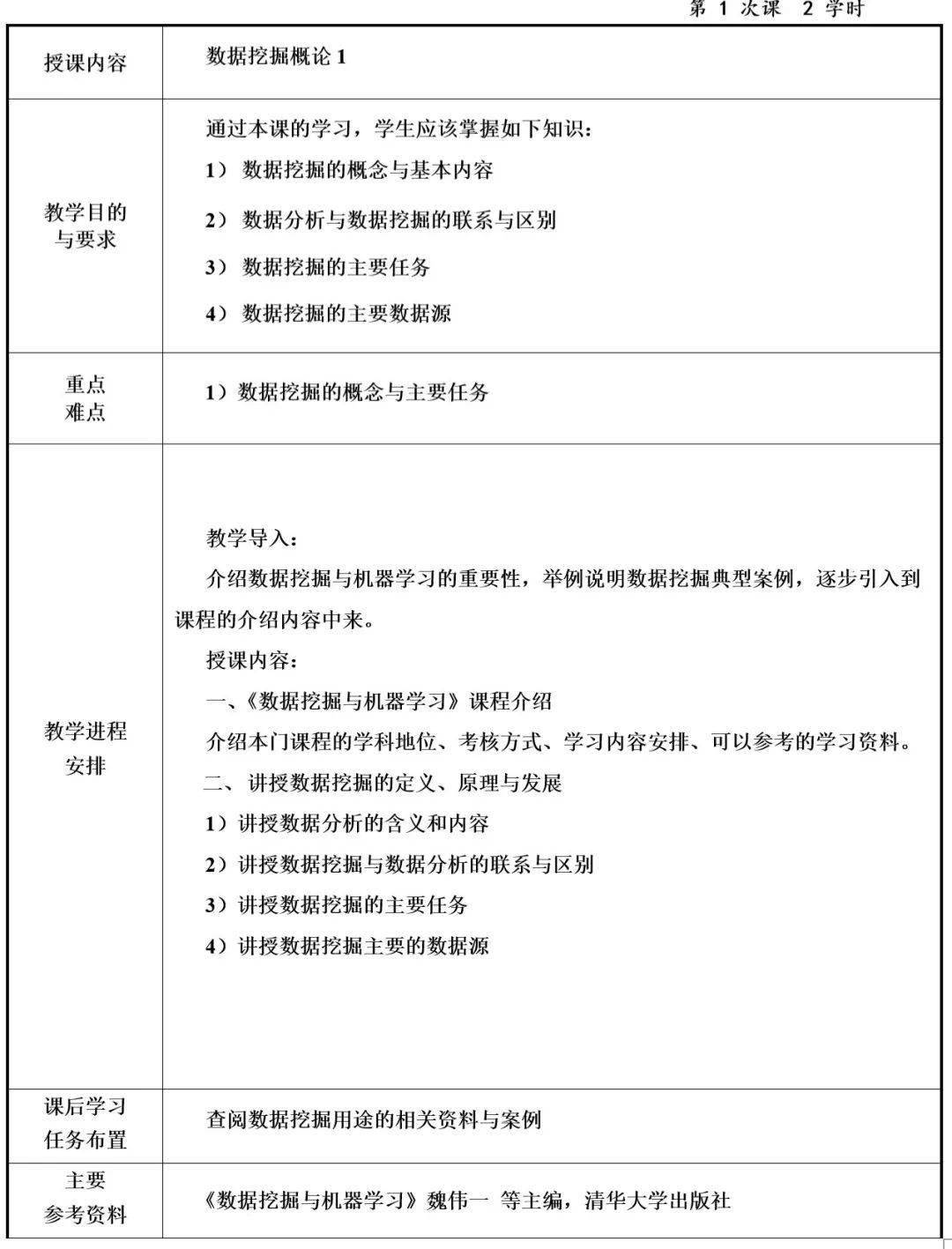
12
教案样例
12
课件样例

完整的教案,请在公众号“书圈”后台回复【9787302663416】下载完整版